Dataset是1.6版本引入的新的实验接口, 整合了RDD的优势(强类型, 支持lambda方法)和Spark SQL执行引擎的各种优化. Dataset可以由JVM对象来构造并且使用transformation来变换(map, flatMap, filter等等). Dataset本身是DataFrame API的一种扩展, 它提供了类型安全, 面向对象的编程接口. Spark 1.6包含了Dataset的API预览, 在接下来几个版本的Spark中我们会持续开发. 和DataFrame类似, Dataset将expression和数据域暴露给query planner, 这样就可以充分利用Spark的Catalyst优化. Dataset也会充分利用Tungsten的fast in-memory encoding. Dataset还提供了编译时的安全检查, 这意味着生产应用在运行前就可以就行类型检查. 同时Dataset还支持直接操作用户自定义的class.
长远来看, 我们期望Dataset成为编写Spark应用程序的有力工具. 我们会沿用已有的RDD API来设计Dataset, 但在数据可以通过结构来表示时可以大幅提升效率. Spark 1.6提供了Dataset的一个预览, 我们会在后续的版本中持续优化.
Dataset API支持scala和Java两种语言, 目前还不支持python, 因为它本身的动态特性很多功能已经支持了(例如, 你可以通过row.colName的方法来获取某一行的某个域). 完整的python支持会在下一个版本给出.
创建Datasets
Datasets和RDD很类似, 不过它不用Java或者Kryo的序列化方法, 而是用特殊的Encoder来序列化对象用于处理和网络传输. 尽管encoder和标准序列化方法都是为了将对象转换为字节流, encoder是动态生成代码, 并且使用一种特殊的格式, 使得Spark可以在上面做诸如filtering, sorting或者hashing的操作, 而不需要将字节反序列化为对象.
// Encoders for most common types are automatically provided by importing sqlContext.implicits._val ds = Seq(1, 2, 3).toDS()ds.map(_ + 1).collect() // Returns: Array(2, 3, 4)// Encoders are also created for case classes.case class Person(name: String, age: Long)val ds = Seq(Person("Andy", 32)).toDS()// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name.val path = "examples/src/main/resources/people.json"val people = sqlContext.read.json(path).as[Person] |
操作Dataset
Dataset是强类型, 不可变的对象集合, 并映射到关系型的schema上去. 参考下面的代码, 从文本中读取文本行, 并切分成单词:
RDD
val lines = sc.textFile("/wikipedia")val words = lines .flatMap(_.split(" ")) .filter(_ != "") |
Dataset
val lines = sqlContext.read.text("/wikipedia").as[String]val words = lines .flatMap(_.split(" ")) .filter(_ != "") |
两种API都可以灵活的运用lambda方法来表述transformation. 编译器和IDE可以理解使用的类型, 并在构建pipeline的时间提供提示和错误信息.
尽管从语法上看起来基本一致, Dataset提供了更强大的关系执行引擎. 例如, 你可以更方便的做aggregation.
RDD
val counts = words .groupBy(_.toLowerCase) .map(w => (w._1, w._2.size)) |
Dataset
val counts = words .groupBy(_.toLowerCase) .count() |
由于Dataset的版本可以充分利用内建的aggregate count, 该计算不仅可以用更少的代码来表述, 也会执行的更快. 如下图所示, Dataset的实现比原生RDD要快的多.
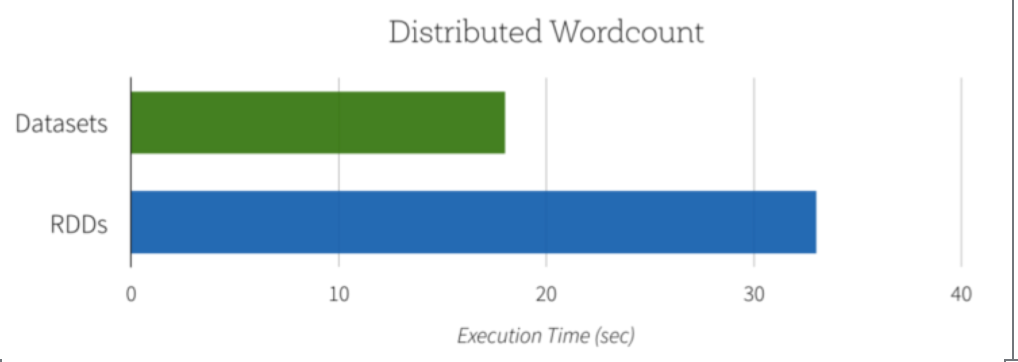
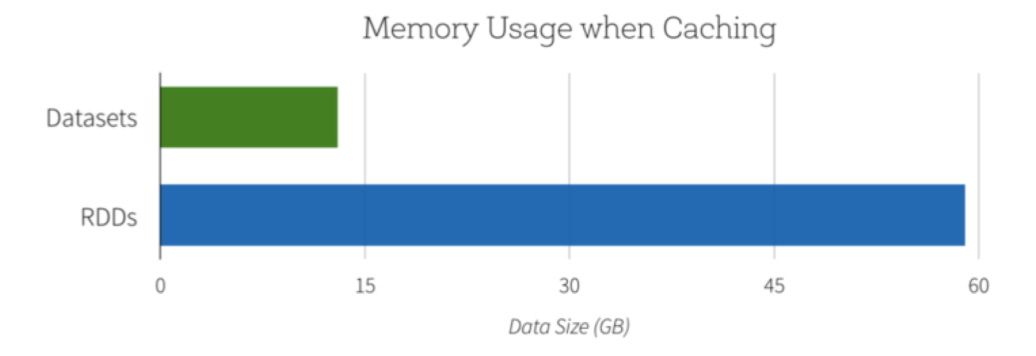
另一个好处是使用新的Dataset API可以降低内存使用. 因为Spark理解Dataset中的数据结构, 它可以在缓存Dataset时使用更节省的内存布局. 在下面的例子中, 我们对比了使用Dataset和普通RDD来缓存百度级别的String的内存使用率. 在两种场景下对数据进行缓存都可以极大的提升后续查询的性能. 不过Dataset encoder可以为Spark提供更多的数据存储的信息, 因此可以节省4.5倍的空间.
Lightning-fast Serialization with Encoders
Encoder是高度优化的并且使用运行时code generation来构建custom bytecode用于序列化和反序列化. 因此, 他们可以比Java或者Kryo序列化更快的操作对象.
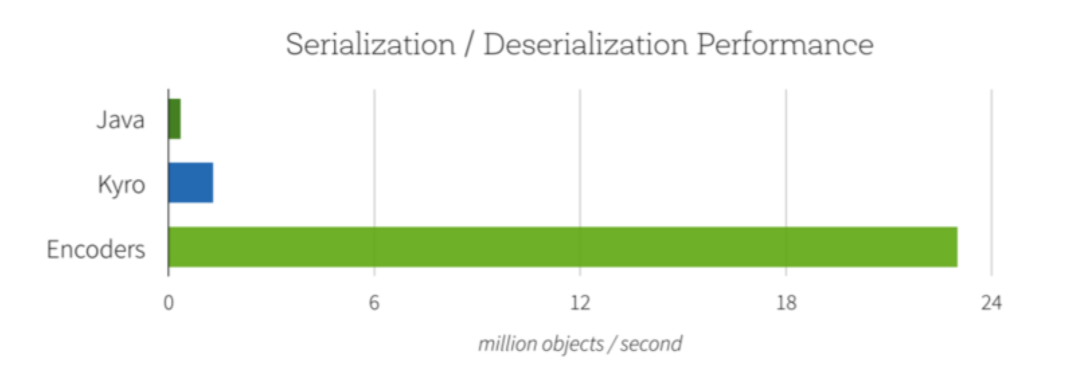
除了速度以外, encoded数据的序列化结果也远比之前要小(2倍), 大大降低了网络传输的开销. 此外, serialized data已经包含在Tungsten binary format中, 这意味着很多操作在这里就可以直接进行, 而不用物化整个对象了. Spark内建支持自动生成原始类型(例如String, Integer, Long等), Scala case classes和Java Beans的encoders. 我们计划将接口开放并允许自定义类型的有效序列化.
无缝支持半结构化数据
encoder可以大幅的提升性能, 也在半结构化数据(如JSON)与类型安全语言如Java, Scala之间搭建了一道桥梁.
例如, 看下面一个关于大学的dataset:
{"name": "UC Berkeley", "yearFounded": 1868, numStudents: 37581}{"name": "MIT", "yearFounded": 1860, numStudents: 11318}... |
用户不再需要手动抽取数据域并cast成自己期望的类型了, 你只需要定义一个类, 声明你期望的结构并将数据映射进去. 列会自动按照列名分配, 类型也会保存.
case class University(name: String, numStudents: Long, yearFounded: Long)val schools = sqlContext.read.json("/schools.json").as[University]schools.map(s => s"${s.name} is ${2015 - s.yearFounded} years old") |
Encoders会检查你的数据是否匹配期望的schema, 并且在你试图错误的处理大规模数据集之前提供有效的错误信息. 例如, 当我们试图使用太小的数据类型, 对象的转换可能会被截断(例如, numStudents大于一个字节, 因为一个字节最多表示255), Analyzer会emit一个AnalysisException.
case class University(numStudents: Byte)val schools = sqlContext.read.json("/schools.json").as[University] org.apache.spark.sql.AnalysisException: Cannot upcast `yearFounded` from bigint to smallint as it may truncate |
在处理映射时, encoders会自动处理复杂类型, 包括嵌套类, array和maps.