python的scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
python和scrapy的安装就不介绍了,资料很多
这里我个人总结一下,能更加快理解scrapy和快速上手一个简单的爬虫程序
首先开始一个scrapy项目
用命令: scrapy startproject 项目名
创建出来的文件如下图:红框是我的命令,蓝框是scrapy自动创建的文件
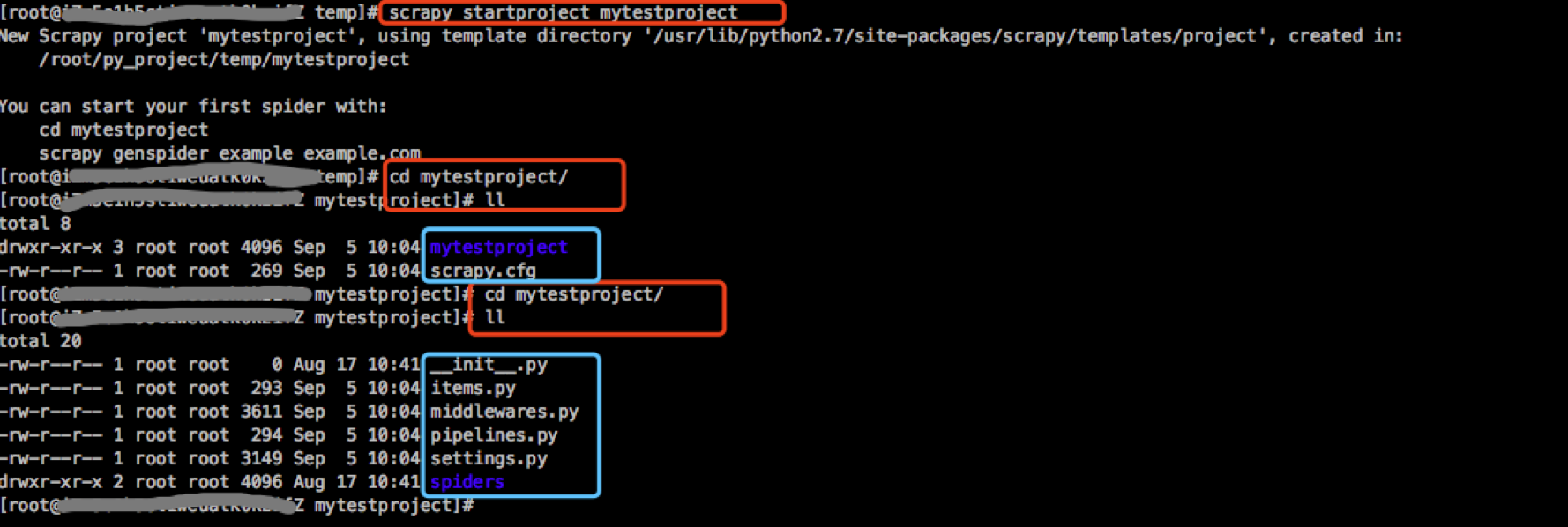
其中各个最常用文件的用处:
mytestproject
–items.py 定义spider.py到pipelines.py中间的数据格式
–pipelines.py 处理爬取到的数据
–settings.py 配置文件,定义有几个pipelines以及他们的优先级,
–spider 爬虫目录
—-spider.py 爬取哪些页面, 如何解析爬取的到的数据,整理数据返回给pipelines.py
我画了一张简单的图介绍一下各个文件之间的关系:
一个url地址对应的数据从开始爬取–>处理结果–>入库(或写文件等) 分别是在哪个文件里做的,如下图:
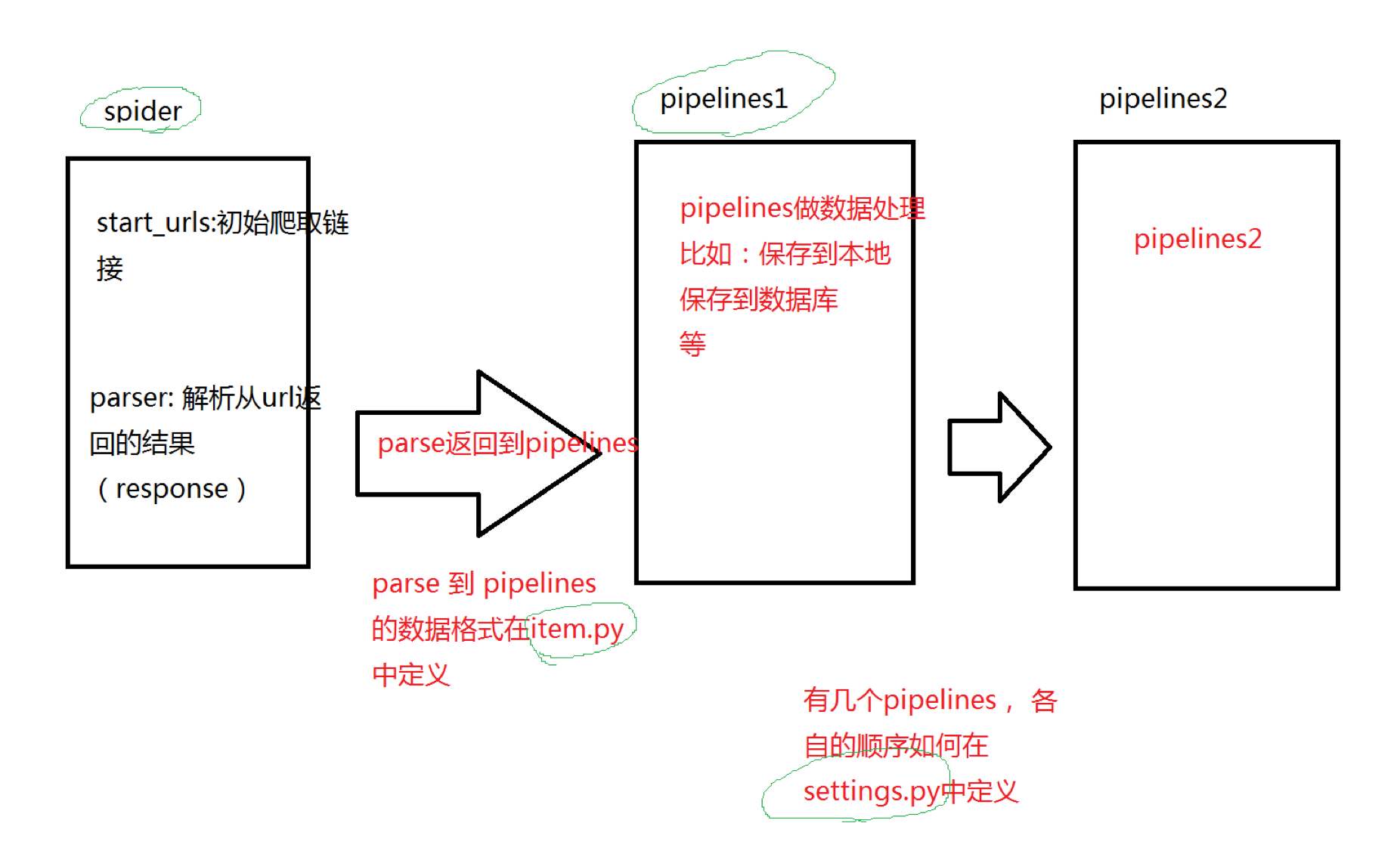
scrapy框架中的各个文件和数据流转大概就是这样,后面我会详细介绍下我爬取zhihu的各个文件的详细代码.
欢迎关注我的公众号,分享面试攻略和技术干货!
