想通过配置调用agg方法, 不知如何构造spark.sql.Column, 所以研究了下, 记录下:
agg方法:
def agg(expr: Column, exprs: Column*): DataFrame = {
toDF((expr +: exprs).map {
case typed: TypedColumn[_, _] =>
typed.withInputType(df.exprEnc, df.logicalPlan.output).expr
case c => c.expr
})
}
传的参数是Column, 但是我用的时候可以这样用:
aggDF = selectDF.groupBy(keysArr: _*).agg(countDistinct("num") as "cd", sum("num") as "sum")
所以有点疑惑 countDistinct(“num”) as “cd” 是Column么?
经过研究发现可以这样写:
先看图, 清晰点, 后面贴代码:
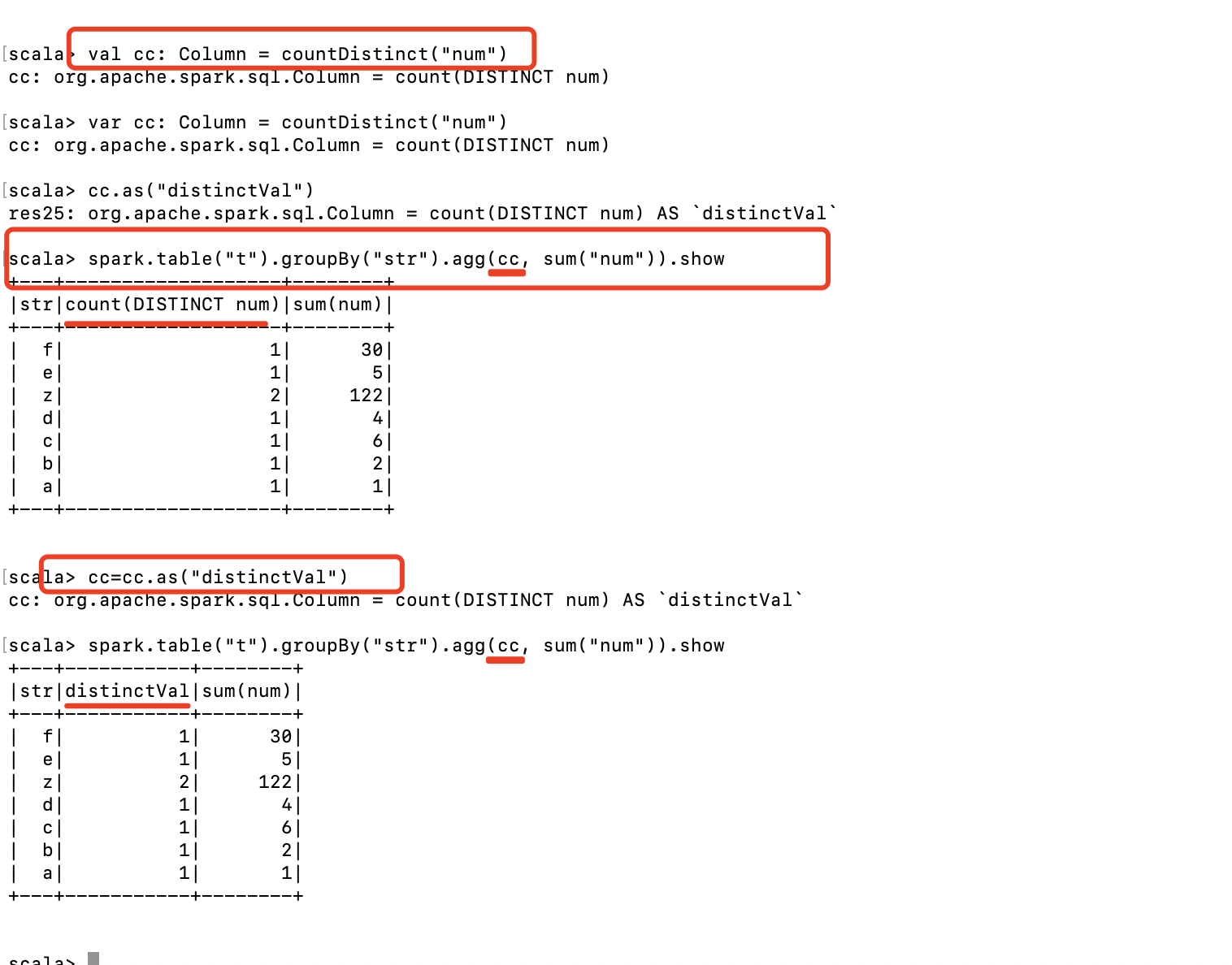
scala> var cc: Column = countDistinct("num")
cc: org.apache.spark.sql.Column = count(DISTINCT num)
scala> cc.as("distinctVal")
res25: org.apache.spark.sql.Column = count(DISTINCT num) AS `distinctVal`
scala> spark.table("t").groupBy("str").agg(cc, sum("num")).show
+---+-------------------+--------+
|str|count(DISTINCT num)|sum(num)|
+---+-------------------+--------+
| f| 1| 30|
| e| 1| 5|
| z| 2| 122|
| d| 1| 4|
| c| 1| 6|
| b| 1| 2|
| a| 1| 1|
+---+-------------------+--------+
scala> cc=cc.as("distinctVal")
cc: org.apache.spark.sql.Column = count(DISTINCT num) AS `distinctVal`
scala> spark.table("t").groupBy("str").agg(cc, sum("num")).show
+---+-----------+--------+
|str|distinctVal|sum(num)|
+---+-----------+--------+
| f| 1| 30|
| e| 1| 5|
| z| 2| 122|
| d| 1| 4|
| c| 1| 6|
| b| 1| 2|
| a| 1| 1|
+---+-----------+--------+